I Stumbled into Data Science by Accident
If a dummy like me can learn to code and analyze data, anyone can!
It seems that people get into data science from all sorts of different backgrounds. It seems clear that there is no “best” way to get into the field. I thought it might be interesting to share my own story.
I spent 15 years working as CEO of a manufacturing company in an LDC (Least Developed Country). Some demographic statistics (Source: http://hdr.undp.org/en/countries/profiles/PNG)
We’d been working to modernize our processes, with some successes and some failures, but we always learned something from the experience. My working life had been one improvement project after another for more than a decade, and honestly I loved it. Perhaps a topic for a future article.
The latest was an ambitious project to change the way we plan and report production.
For many years, our production planning process was unorthodox. Without consultation or communication with other stakeholders, the production manager would arbitrarily decide their production plan. This plan lived on an excel spreadsheet, which only the production manager had access to. The first time production data of any kind entered the company’s Enterprise Resource Planning system (ERP) was 24 hours after a days worth of production had been completed. Hand-written paper production record sheets were delivered to two production clerks who’s sole mission was to create new work orders in the ERP to match the production sheets, and immediately close the work orders. The quantity of finished goods would increase, and raw materials would decrease. We called this “back-flushing”. Everyone knew that it was not the way things should be done, but like many companies we were change averse.
At the risk of stating the obvious, this seemed to be a terrible way to run production planning and reporting. The list of problems created by this approach was long, but here are a few:
I could go on and on, but you get the picture.
We finally decided to fix this after we’d racked up a few wins on low-hanging fruit. We knew this would be a tough one, and the team needed a few wins to give them the confidence to commit to a change of this magnitude, which would involve and affect so many stakeholders.
This will sound really obvious to the reader, as this quite standard and how it should have been done all along. Why the company started “back-flushing” in the first place I’ll probably never really know.
What is important to understand is why it was so hard to change: People and organizations are inherently change-averse. Change is hard, risky and expensive in both financial and non-financial ways. Technology was never the limiting factor in effectively making a sustainable change. Winning hearts and minds was the critical ingredient.
It took a LOT of time and work to get to the point of going live, but we did it, and the team felt a great sense of pride and achievement. Things seemed to go well for the first few months after go-live, but then we noticed strange, sometimes nonsensical numbers appearing in the General Ledger.
For example, on occasion the value of raw materials being deducted from stock was greater than the value of finished goods being produced. Think about that for a second: This is obviously ridiculous, but no one could explain why it was happening.
The problem was that all the manufacturing accounting transactions were transferred from the manufacturing module of the ERP to the general ledger in an automatic process. The records of this process were captured and recorded in txt files, which we referred to “daybooks”. Each daybook might contain 15,000 or more unique transactions.
They say a picture is worth a thousand words, so here are a few screenshots to illustrate. This is quite a small file as it happened on the 2nd of January which is normally a pretty quite time:


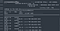
Its quite obvious that there are a number of issues with this file:
No-one knew how to go about finding the “needle in a haystack” buried in the 100mb+ of data for each month in order to find a pattern of erroneous transactions. We all had theories, which we tried to test on small samples of data, but failed each time.
This continued for several months, during which time we were forced to make increasingly large “gross” general ledger adjustments to make the figures look like we believed they should. This is a horrible feeling for any manager, as you have no real idea if you’re reporting the truth, or misrepresenting the performance of the company.
To make matters worse, the magnitude of the problem was material and growing.
The pressure and frustration built to the point where the team became so frustrated and disillusioned, that they reached a general agreement that the best solution was to roll back and revert to the old way of doing things. Having invested so much time and effort to make this a reality this was a crushing blow to the team. I am blessed (or cursed) with stubbornness. Its a mixed blessing at best. Consequently I was the one dissenting voice.
I made a commitment to the team: “give me 30 days. If I can’t solve it in that time, I will agree to revert. During that 30 days I will only focus on this problem. I need you all to step up and take care of my normal duties so I can focus”. I was the CEO, so they had no choice but to agree. Naturally there was a great deal of skepticism: how could I succeed when accountants, IT professionals, and consultants had failed? Very valid doubts, as I am none of those things. I’m a generalist: jack of all trades and master of none.
Still, a deal is a deal.
The process I followed is described below. In hindsight I now know that it wasn’t a great process, but at the time I was figuring it out as I progressed. I’ll continue to improve.
At this point, which was day 5, I had enough clean information to diagnose the problem, but I’ll come back to that later. In the course of cleaning this data, I realized that there was a lot of valuable information in these files that we were not using.
This is information could be used for ongoing performance management, so it made sense to shift the goal post from just solving the immediate problem, to establishing a repeatable process that would allow production managers to easily analyze the transactional data contained in these files.
Its a rather long script so this is just the head.

Findings:
A number of problems became evident based on the data.
A table will help understand the next few points


This is a simple approach. One could take this to the nth degree. Having more variance accounts that allow greater granularity, but too much granularity can be problematic. For an operation of our size, we felt that this would be sufficient. KISS (Keep it Simple) is a good rule of thumb.
This was the root cause of the large erroneous numbers we were seeing at GL level.
Solution:
Lessons for me:
Thanks for reading.
This content was originally published here.