Large Language Models are powerful. But can you trust them with your business?
In 2025, AI “hallucinations” are a major problem, with a growing number of US companies reporting issues caused by AI-generated misinformation. Standard LLMs can’t access your private data, their knowledge is months out of date, and they often make things up.
This is a huge risk.
For this month’s V-Techtips, our top-talent Backend Software Engineer, Leon, breaks down the solution.
A breakthrough technique called Retrieval-Augmented Generation (RAG) is changing the game. It connects LLMs to your company’s real-time, private data. This guide explains how RAG makes AI smarter, more accurate, and truly ready for business.
What is RAG and Why is it Important?
Simply put, RAG is an architecture that allows an LLM to “look up” information from an external knowledge source (like a company’s internal documents, product databases, or recent internet articles) before generating an answer.
This process addresses the core problems of LLMs:
- Combating Hallucinations: Instead of “inventing” an answer, the LLM bases its response on retrieved information, making the answer significantly more accurate and trustworthy.
- Real-time Knowledge Updates: While re-training an entire LLM is costly and time-consuming, updating the knowledge base for RAG is very fast. This ensures the LLM always has access to the most current information.
- Accessing Proprietary and Private Data: RAG allows businesses to securely connect LLMs to their internal data repositories, creating intelligent virtual assistants with deep knowledge of company products and procedures.
Key Benefits of the RAG Technique
Applying RAG to AI systems brings outstanding benefits, especially within a business context:
- Increased Accuracy and Reliability: Responses are generated based on actual data, minimizing the risk of providing incorrect information to users and customers.
- Enhanced Transparency: RAG systems can cite the source of information, allowing users to verify and validate the answers.
- Cost-Effectiveness: Compared to “fine-tuning” an entire LLM for specific tasks, building and maintaining a RAG system is often more economical.
- Data Security: A company’s internal data remains under its control; it is only used to retrieve information when needed rather than being incorporated into model training.
- High Personalization: The knowledge base can be easily customized to create specialized experiences for different departments or user groups.
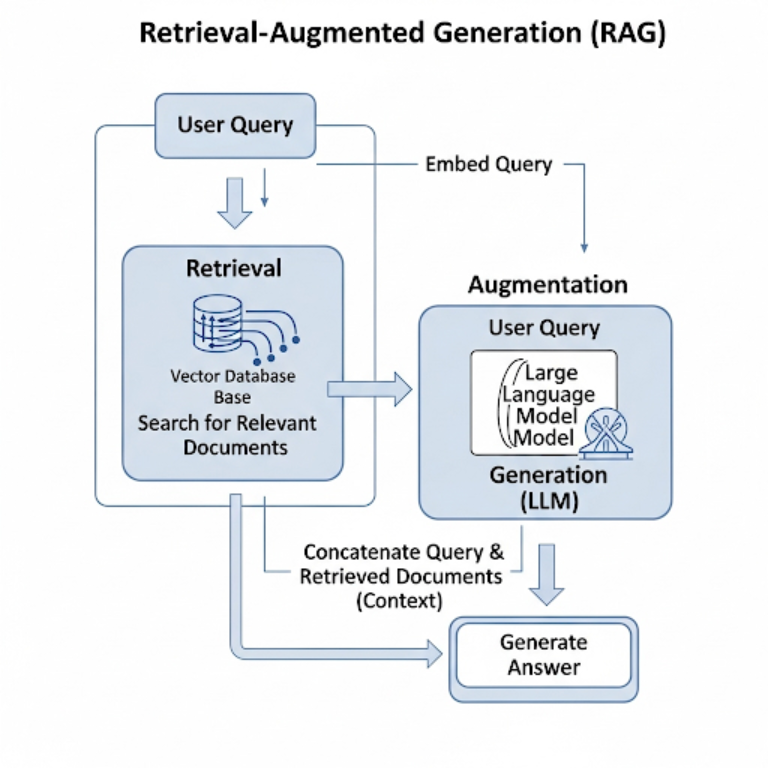
How Does RAG Work? The Technical Process
The RAG architecture consists of two main phases:
Phase 1: Data Indexing (performed once or periodically)
This is the process of preparing the “knowledge library” for the LLM.
- Load Data: The system gathers data from various sources (PDFs, Word documents, websites, databases, etc.).
- Chunk: The data is broken down into smaller, manageable pieces for easier search and processing.
- Embed: Each data chunk is converted into a numerical vector (embedding)—a mathematical representation that a computer can understand contextually.
- Store: These vectors are stored in a specialized database called a Vector Database.
Phase 2: Retrieval and Generation (occurs in real-time)
This process happens when a user asks a question.
- Query: The user’s question is also converted into a vector.
- Retrieve: The system searches the Vector Database to find text chunks whose vectors are most like the question vector. This retrieves the most relevant information.
- Augment: This relevant information is combined with the user’s original question to create a new, context-rich “prompt.”
- Generate: This comprehensive prompt is sent to the LLM. The LLM now has all the necessary context to generate an accurate and relevant answer.
Practical Applications of RAG
We recognize the immense potential of RAG to improve operational efficiency and create smarter products:
- Internal Support Chatbots: Building virtual assistants for HR, IT, or Finance departments that can accurately answer questions about company policies, leave procedures, software guides, etc.
- Advanced Customer Support: Creating chatbots that can look up user manuals, warranty policies, and customer interaction history to provide immediate and precise answers.
- Specialized Information Retrieval Systems: Developing tools to help professionals (lawyers, doctors, engineers) quickly search for and summarize information from thousands of complex documents.
- Content Personalization: Recommending products, articles, or courses tailored to a user based on their history and behavior.
Conclusion
RAG is more than just a technical solution; it is the critical bridge between the vast power of large language models and the real-world, dynamic data of businesses. By equipping AI with the ability to “learn” from proprietary data safely and effectively, RAG is ushering in a new era of intelligent, reliable, and genuinely helpful AI applications.
Beyond the Basics: The Future of RAG
Mastering RAG is the first step, but to truly unlock its full potential, we can explore more advanced techniques. At Vinova, we are continuously researching and applying these methods to create breakthrough AI solutions, including:
- Advanced Retrieval Techniques
- AI Agents
- RAG on Structured Data
- Evaluation Frameworks